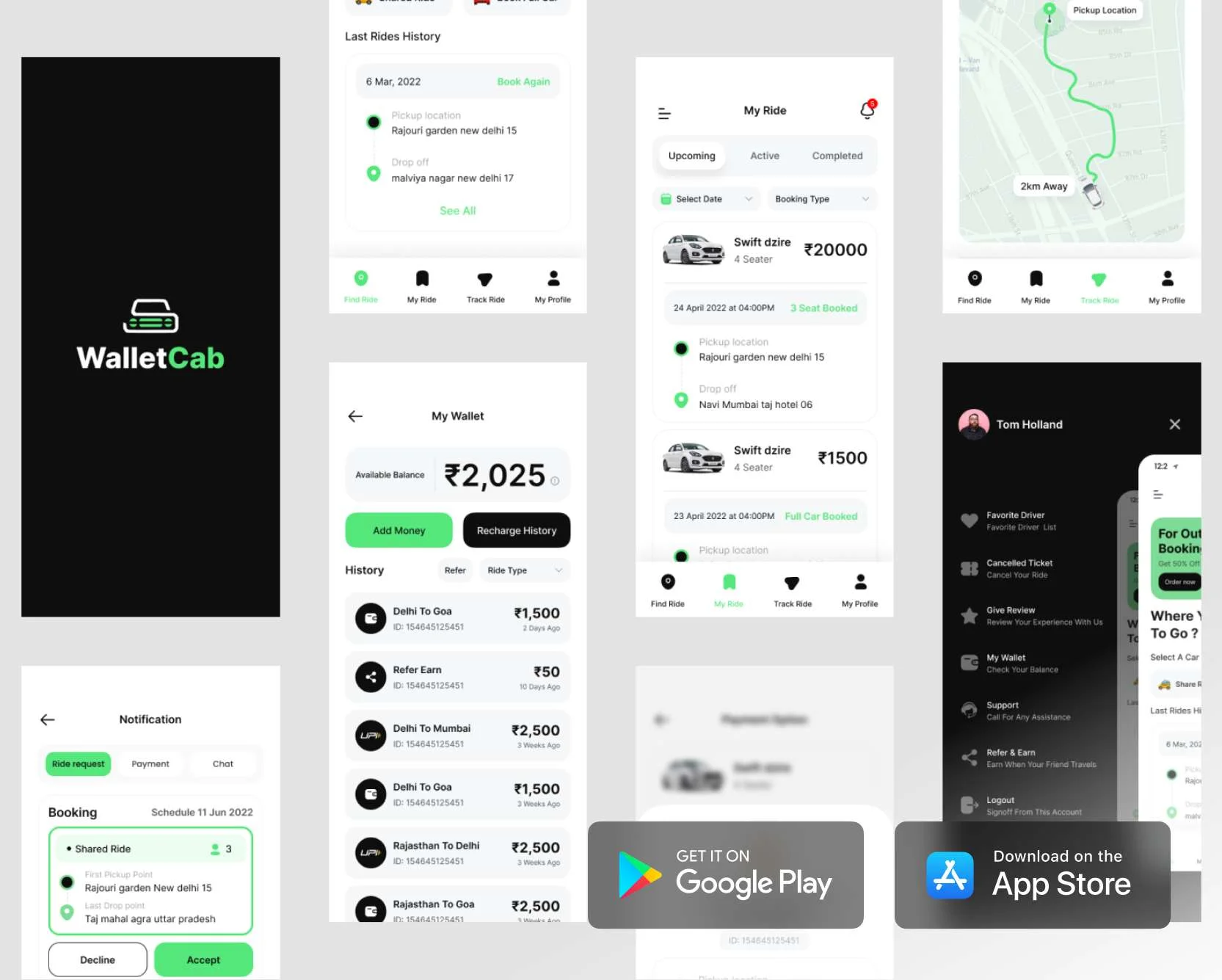
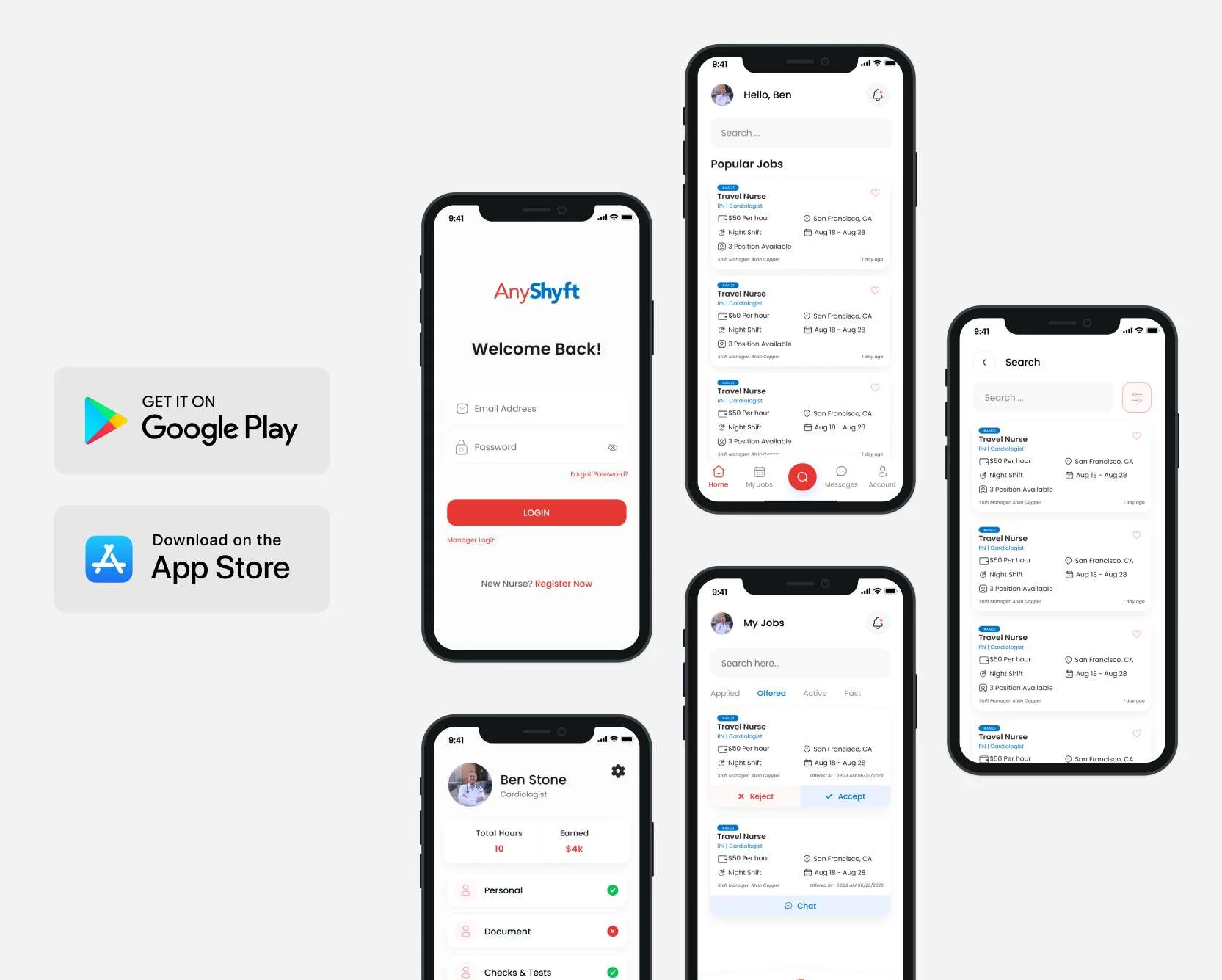
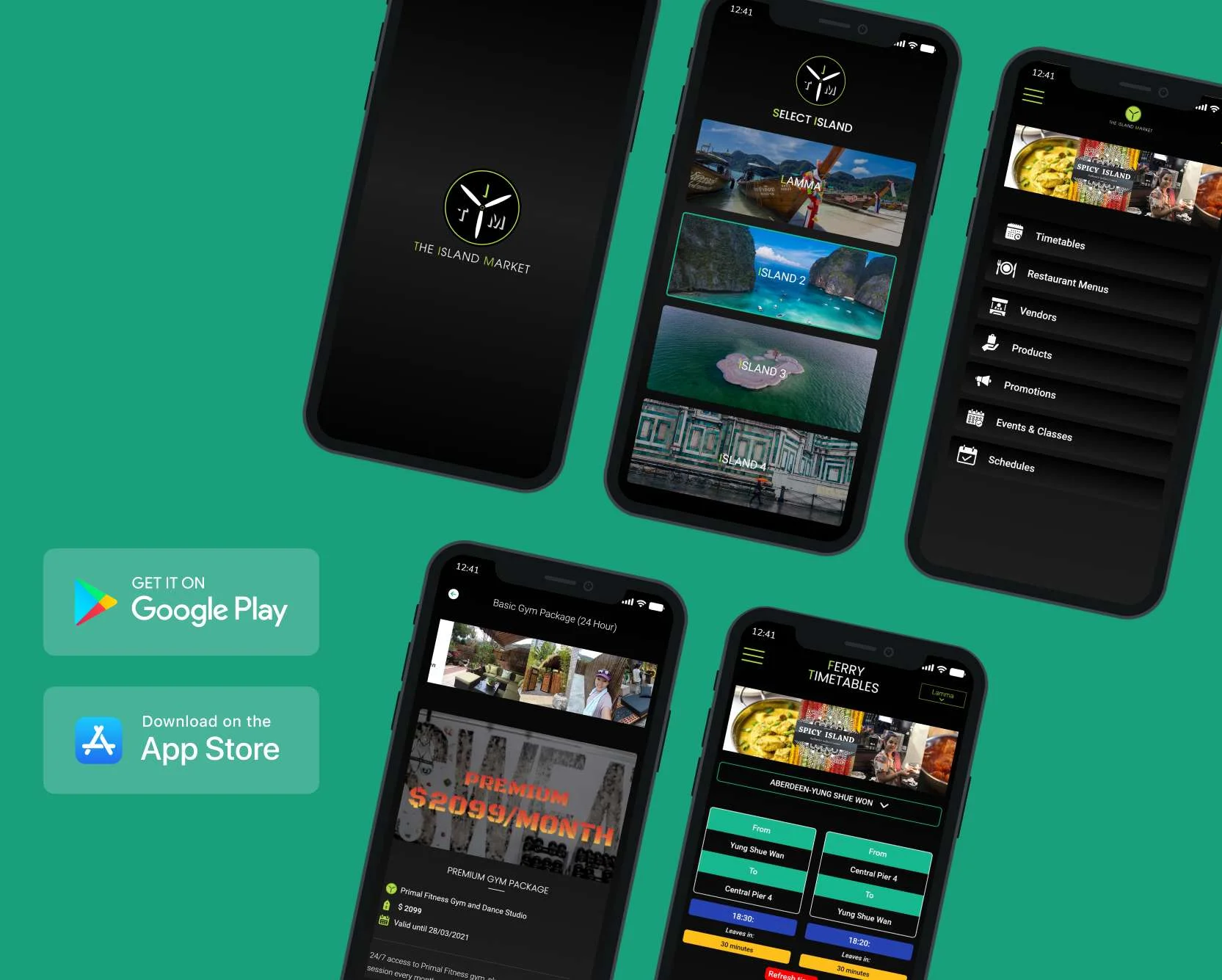
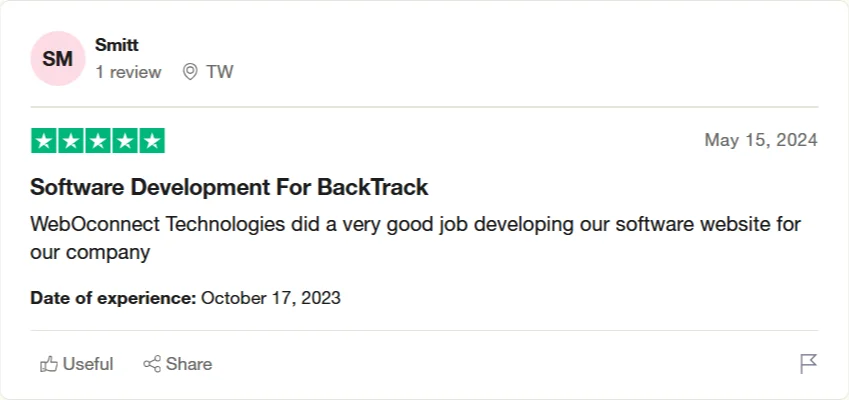
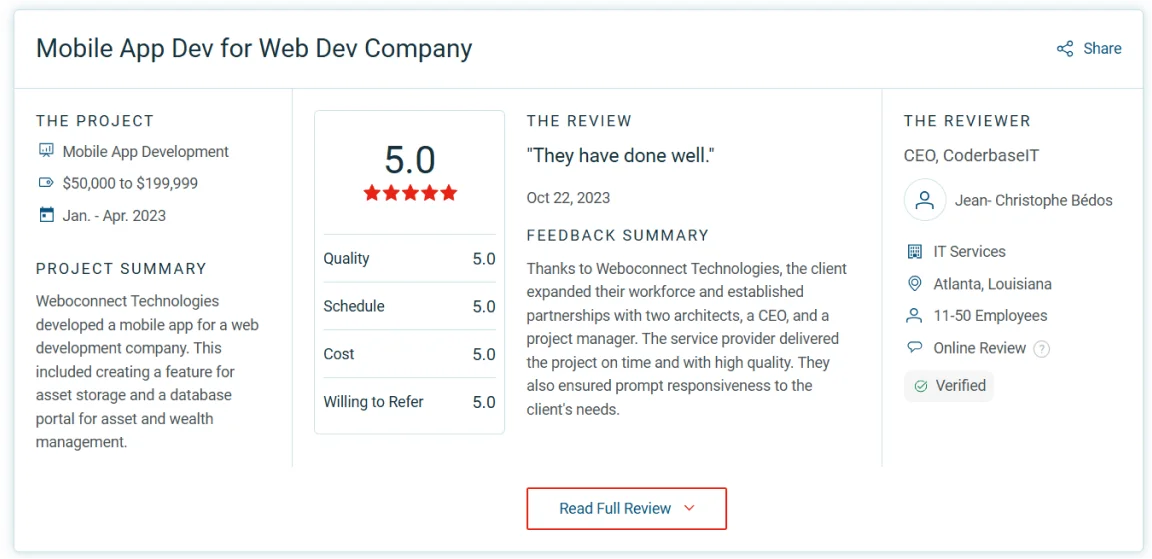
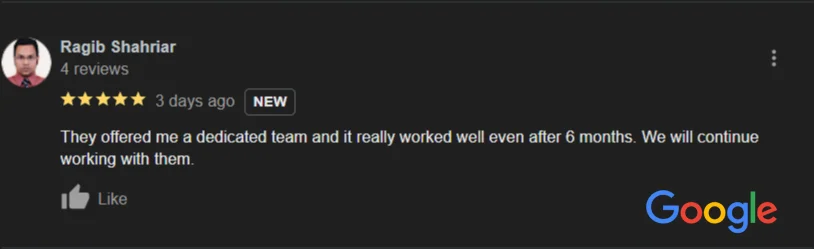
We provide continuous system monitoring, timely updates, and expert issue resolution, ensuring your digital platforms operate seamlessly with maximum uptime and minimal disruptions.
Pioneering customized web and mobile application development with a focus on excellence.

Global Clients
Successfully Projects
Years of Excellence
Client Retention




With expertise in almost every programming language, our 4,000+ team delivers dynamic solutions that align with modern business demands.
Node Js
React Js
Laravel
Python
Flutter
Java
Swift
Codeigniter
Artificial Intelligence
Machine Learning
Kotlin
React Native
Node Js
React Js
Laravel
Python
Flutter
Java
Swift
Codeigniter
Artificial Intelligence
Machine Learning
Kotlin
React Native
When excellence matters, choose WebOConnect. We combine creativity and precision to deliver superior web and mobile solutions, tailored for your success.
Every partnership reflects the trust and confidence our clients place in us. Together, we create impactful solutions that inspire growth and pave the way for long-term success.
Healthcare
Finance
Retail & E-commerce
Education
Travel & Tourism
Real Estate
Media & Entertainment
Automotive
Lifestyle
Productivity
Beauty
Communication
Healthcare
Finance
Retail & E-commerce
Education
Travel & Tourism
Real Estate
Media & Entertainment
Automotive
Lifestyle
Productivity
Beauty
Communication

What Is the Real State of AI Integration for Businesses Today? The noise around artificial intelligence is deafening. Every vendor promises the unattainable. Organizations severely underestimate what it takes to move from a prototype to a production ready system. It takes serious engineering. Companies jump into projects without a clear goal. They burn through cash, frustrate their teams by skipping the absolute basics. Treat AI like any other major infrastructure investment. Finding an experienced AI software development company makes a massive difference right out of the gate. You need people who know exactly where the landmines are hidden. We are moving past the era of casual experimentation, Business leaders want measurable outcomes. They want tools that work when plugged into legacy systems. If your project doesn't solve a specific operational headache, it probably should not exist. How Should You Approach Planning Before Burning Cash? You can't throw money at an algorithm and hope it learns. Planning dictates your survival. First identify the exact problem. Not a vague idea like making things faster. You need a specific target. Think about reducing customer support ticket times by thirty percent. That defines a solid baseline. Data is your next massive hurdle. If your data is a mess, your output will be a mess. Most companies assume their databases are ready. They're almost always wrong. Proper data preparation is non-negotiable. You must audit what you have and figure out what is missing. Partnering with a solid AI software development company early saves you from building on quicksand. They tell you exactly what pipelines need fixing immediately. You are not just writing code anymore. You are training logic. Start small. Prove the concept. Scale up only after the data proves it works. What Are the Core Components and Top High Value Use Cases? Let's look at what actually moves the needle. The engine running these operations usually relies on specific machine learning models trained entirely on your proprietary data. That is where your real competitive advantage lives. You want a system understanding your specific industry jargon. Customer service is the obvious starting point. Tools powered by natural language processing handle massive volumes of basic inquiries. They route complex issues to human agents. This cuts wait times drastically. Supply chain logistics heavily utilize predictive analytics right now. Algorithms analyze weather patterns and historical sales to prevent stockouts. That is real money saved. Quality control in manufacturing is another huge growth area. Computer vision systems inspect parts on assembly lines instantly. An established AI software development company can look at your operations and instantly spot these high value opportunities. They know what works because they have deployed it globally. What Does a Reliable Implementation Framework Look Like? Building these systems requires strict discipline to prevent total chaos. You start with the data ingestion layer. You pull information from your CRMs and outdated flat files. Then comes the transformation layer. You clean the data and make it digestible. Mess up this step and the whole house of cards collapses. Next is the actual modeling environment. This involves rigorous testing. You validate the models against real world scenarios. You deploy custom solutions securely. They must not leak sensitive company data to the public internet. Ignore compliance protocols and you face massive regulatory fines. Once deployed, you need an inference engine that handles the load. This takes robust cloud architecture. A competent AI software development company sets up continuous monitoring from day one. Models degrade over time. Customer behaviors shift. You need a framework that automatically flags performance drops and triggers retraining cycles immediately. What Are the Real Costs, ROI Metrics, and Best Practices? Entry level automation projects run between twenty and eighty thousand dollars. Mid level applications with custom integrations cost up to two hundred and fifty thousand. Enterprise grade infrastructure requires half a million or more. Ongoing cloud compute costs easily take another twenty percent of that budget annually. But the return on investment completely justifies the upfront pain if executed correctly. You measure this through strict reductions in operational costs. Think fewer support hours and reduced equipment downtime. If your predictive engine increases cross sales by five percent, the system pays for itself in months. Bottom line. Best practices are simple. Don't build from scratch if an existing API works. Focus relentlessly on data quality. Invest heavily in change management. Your employees need training. Hiring an experienced AI software development company ensures you avoid these rookie mistakes. They keep the project grounded in reality. How Do We Wrap This Up for Maximum Impact? The global technology landscape shifts incredibly fast today. Brand new models drop every single week now. But the basic rules of running a successful business have not changed one single bit. You still need to solve real problems for your customers. You still need to watch your profit margins closely. Artificial intelligence is simply the newest lever to achieve those critical goals. Stop getting distracted by all the hype. Focus strictly on your internal data instead. Pick a highly specific, painful problem in your daily operations. Build a minimum viable product to tackle it. Prove that it actually saves money. Then slowly scale it across the entire company.Calculate the exact hiring cost of dedicated resources using WebOConnect’s quote calculator. Frequently Asked Questions? 1.How much does a basic business AI project cost? Basic implementations usually start around twenty thousand dollars. Costs easily scale up to eighty thousand depending on the integrations required. Start small, validate the tool, and prove the core value first 2.How long does it take to deploy an initial model? Expect a proof of concept to take anywhere from four to twelve weeks to complete. This timeline depends heavily on how clean your existing data is right now. Messy databases cause significant delays. 3. Do we need to hire an internal team immediately? Not usually. Many businesses partner with external engineering experts to build the first few applications. This keeps your initial overhead low while you test the waters. Hire internal engineers later. 4. What is the biggest hidden cost in these projects? Data preparation absolutely consumes the largest chunk of your budget. Many companies are shocked when formatting takes up sixty percent of the project time. Ongoing cloud computing costs also surprise executives. 5.How do we measure success for these initiatives? Track strict business metrics like reduced operational costs or increased daily sales conversions. Never measure success purely by technical metrics alone. If it doesn't improve the bottom line, it fails. 6. Are prebuilt solutions better than custom builds? Prebuilt tools always offer a faster and cheaper starting point for solving common business problems. Custom builds are only necessary when you have highly unique workflows. Always test an off the shelf option first. 7. What causes most of these implementations to fail? Lack of specific business goals and poor data quality are the two biggest project killers. Companies also regularly fail to train their staff properly. Without solid user adoption, algorithms are completely useless.
Read More
If organizations plan to hire dedicated developers in 2026 they then enter a market shaped by senior scarcity, AI output, and nearshore preference. Hiring is higher than usual. The numbers show 74% of developers say finding a job remains difficult. Senior hiring grew 19%, Lead roles 22%, Junior only 9%. The supply skews hard toward experienced engineers. Meanwhile, 90% of developers now use AI assistants. AI writes roughly 29% of the code and 67% say the pressure to ship faster has increased. The current situation has also made budgets tight, expectations climb. Early-2026 research links nearshore work to higher success rates, better quality, less PM overhead, fewer communication breakdowns than far-offshore setups. Methodology, not geography, moves the cost needle most. A 2008 trust study also found communication improves when trust is present. It reduces opportunistic behavior. How should planning be handled? Teams that hire dedicated developers without documenting scope report higher rework, so successful briefs define a 90-day outcome and list features, integrations, and compliance needs, then select from three engagement models. Staff augmentation fills gaps quickly which is often 2 to 4 weeks. The dedicated team model provides a fully cross-functional unit for long-term work. Fixed-price fits only locked scope not leading to complete potential. Mixing models mid-project raises overhead. Global hourly rates span $15 to $80, monthly offshore engagements range $800 to $8,000. Documenting time zone overlap early prevents friction later. By 2025, US firms had integrated remote teams into agile workflows. Nearshore hiring in Latin America grew for overlapping hours. A 2025 study found team composition significantly influences performance in onsite-offshore teams. Heterogeneities hinder knowledge growth leading to better output, exceeding expectations. Operational capabilities in mediated offshore models also depend on human resources and organizational age. What are the core components that actually drive cost? Not every project requires a full time in house hire. The modern contract economy offers distinct paths to get your code written. You need to match the engagement model to your specific risk tolerance and timeline. First, there's the classic fixed price contract. You hand over a scope of work, they give you a price, and they deliver the product. It sounds incredibly safe for your budget but rarely survives contact with reality. Software requirements change weekly due to user feedback. Fixed price contracts reduce agility and often leads to rushed, brittle code at the finish line because the vendor just wants to close the ticket. Then you have standard staff augmentation. This is where you lease talent by the hour to plug gaps in your existing roster. It works exceptionally well if you already have robust engineering processes. The most practical approach for scaling companies is often to hire dedicated developers through a structured agency. This model gives you a full time engineer who acts like an internal employee but remains on the vendor's payroll. They work over time, work for the company like their own, be accountable and align with your company. It's one of the most reliable staffing solutions available because it balances accountability with flexibility. What framework should teams follow to hire? A documented framework helps companies hire dedicated developers in under two weeks. Start with a one-page brief, Keep it tough. Then source from two channels max. More channels increase noise. Step three is a vetting process based on real work. Data shows 66% prefer practical challenges over puzzles. So use a paid 4 to 8 hour task mirroring production. Then a trial week with repo access. Then contract with IP transfer and security standards. Dedicated teams report 95% plus client retention when knowledge stays in the team. When a freelancer leaves, knowledge walks out. What are the best practices in 2026? Organizations that retain talent after they hire dedicated developers integrate them into Slack, Jira, Zoom, with no separate channels, and document expectations with agile ceremonies included. Security follows SSO, least privilege, mandatory review. Providers hold CMMI 5, SOC 2, ISO 27001. Yet 40% plan to leave within a year, citing pay and growth. Retention correlates with learning paths and centralized documentation. Best practices measure outcomes not hours. Velocity. Defect escape rate. Nearshore teams see fewer communication problems. Heterogeneous teams without planning show more “latent” errors. Centers that adjust working hours for overlap report fewer delays. Research notes “nearshore” clearly reduces management effort and improves quality today. Summary Building a great engineering team (and the larger company around that team) takes time, but most importantly it is a patience game. The days of treating code like a commodity are gone. The world is too competitive and good talent knows its worth no matter where you are. Map your technical needs against your actual management bandwidth before burning a dime. Pick an engagement model that works with your roadmap, not against it. Screen heavily for problem solving and communication, not just textbook knowledge. FAQs 1. How much does a senior offshore software engineer actually cost? In India, seniors usually run $45-70/hour (about $2500-$12k/month based on stack & engagement). Across offshore markets, you’ll see seniors going for $4k-6.5k/month. South Asia hovers at around $30-60/hour, while North America lands at $140-200. 2. How long should the technical interview process take? Five to seven business days, max. Move faster and you'll miss red flags in their code. Drag it out and you'll lose the best people to faster offers, guaranteed. Keep it tight: a quick screening call, one live technical, and a final culture-fit chat. That's it. No marathon loops. 3. Do I need a technical co-founder to build a remote team? You don't need a co-founder, but you do need understanding of the final product and making the technical team understand, also keep note of source code and details related to the final output making you independent. If that's not you, hire a fractional CTO, even part-time, to understand candidates and review the early architecture. 4. What is the biggest hidden cost of remote engineering? The largest hidden cost is always management overhead and the cost of poorly written code. If your internal team spends 15 hours a week fixing bugs created by a remote worker, your cheap hourly rate is actually costing you a fortune. Quality assurance and rework will drain your budget if vetting is poor. 5. Should I pay developers by the hour or a flat monthly fee? A flat monthly fee for a full time commitment is usually the best approach for ongoing product development. It creates predictability for your budget and gives the engineer a sense of stability. Hourly billing makes sense only for short term maintenance or highly specialized consulting work. 6. How do I handle timezone differences effectively? You must mandate a minimum of three to four hours of overlap between your core team and the remote engineers. Use this synchronous time strictly for unblocking tasks, code reviews, and sprint planning. Keep all other updates asynchronous through well written documentation and task trackers. 7. Is it safe to share my proprietary code with an external vendor? Yes, it's safe, as long as you put the right legal and technical safeguards in place from day one. Use solid NDAs and make sure the contract clearly gives your company all the IP rights. Then lock down repo access with role-based permissions and run regular security audits.
Read More
What should you know first? German law doesn't care about the spark in your head. It cares about what you build. Code. Designs. The name users see. How you keep secrets. That's it. If you want to protect app ideas in Germany, start with this legal fact. Sec. 69a UrhG protects software in any form, even drafts. Ideas and principles underneath? Not protected. Every commentary says the same. The code gets copyright, the concept stays free. How do you plan before sharing anything? The first move to protect app ideas is to separate ownership from the person. Most founders in Germany spin up a UG or GmbH early. Not for tax tricks. Because Sec. 69b UrhG puts exploitation rights with the employer for employee-created software. Clean. Simple. For freelancers, German law implies limited usage rights under the purpose-of-transfer doctrine (§31 Abs.5 UrhG) if you have no written contract. You can use what you paid for, but those implied rights are narrow and non-exclusive. To secure exclusive, worldwide rights, a written transfer remains practically mandatory. That's why an app development agreement matters before the first commit. Next, confidentiality. An NDA for app development works in Germany, courts enforce clear ones. But the Trade Secrets Act adds three hurdles. Is it a secret? Does it have commercial value? Did you take appropriate steps? That means limit repo access. Mark decks vertraulich. Log who saw what. A template without behavior fails in practice. This is basic legal protection for startups, not paperwork theater. What are the core parts of app intellectual property Germany uses? You cannot protect an app idea as an abstract thought, only its expressions. So you stack tools, each does one job. Copyright for mobile apps is automatic. Covers source, UI elements, graphics, docs. Doesn't cover the function. Keep Git timestamps, Figma versions, dated builds. That's your proof trail when someone claims they wrote it first. A software trademark Germany filing is for a brand. File at DPMA, classes 9 and 42 for most apps. EUR 290 electronically for up to three classes, EUR 100 each extra. Ten years, renewable. Do it before launch. I've watched teams rebrand at month nine because they skipped the search. Expensive. A patent app idea Germany founders ask about? Usually no. Patents aren't for business methods. They're for actual technical inventions. Got real tech? Then budget for it. Seriously. Filing starts cheap, around EUR 40 to 60. The examination is at least EUR 350. After that the annual fees creep up. Year three is EUR 70. By year twenty you're at EUR 2,030. And that's before the attorney. Expect another EUR 3,000 to 6,000 on top. Most consumer apps skip this and invest in brands and contracts instead. Trade secrets cover know-how you don't file. The law applies, but only if you act like it's secret. NDAs plus access logs plus marking. That's the combo German courts look for. No theater. What step-by-step framework works in Germany? This framework is how teams protect app ideas without wasting money on unnecessary filings. Document the concept first. One pager, sketches, export a dated PDF, store it in the company drive, not your personal Dropbox. Incorporate, make the entity the owner from day one. Run a trademark search in DPMAregister and EUIPO, then file early. If you need speed, pay EUR 200 for accelerated examination, and make a decision within six months if you cooperate. Sign NDAs before any deep dive, define purpose and term and return or deletion. Contact everyone. Freelancers get full IP assignment to avoid relying on implied narrow rights. Employees fall under Sec. 69b for software and the Employee Invention Act for inventions. Staff must report inventions, and under the reformed ArbnErfG the rights automatically transfer to the employer unless the employer explicitly releases the invention in text form within four months. Rights do not revert unless actively released, though compensation remains due. Use a private repo. Turn on access logs. Require signed commits. Get your DSGVO privacy policy, terms, and imprint live before beta, not after. Do it in that order and your chain of title stays clean. Skip one piece and you'll be patching holes later. So what actually works after launch? Long-term habits are what actually protect app ideas after launch. Keep one folder for all signed NDAs, assignments, licenses. Investors will ask, missing papers kill deals. Localize templates to German law and jurisdiction, reference BGB and GeschGehG, don't just use a US form. Monitor app stores monthly for copycats, your trademark gives you a fast takedown. Check open-source licenses before merging, non-compliance can lead to copyright infringement even for partial code, and Sec. 106 UrhG allows criminal liability. Train the team. Most leaks aren't hackers. They're screenshots. Shared test accounts. Sloppy Slack threads. Renew your marks at year nine, not year ten. Set the reminder now. It's boring admin work. That's what wins cases. Summary Copyright starts the second you type. No forms. No registry. Trademarks? They lock the brand at the DPMA, ten years at a time. Patents cover real technical inventions for twenty years, not typical app logic. Trade secrets work only if you take real steps, not just a signed PDF. And employees versus freelancers? Completely different rules for who owns what on day one. That's the whole map in five lines. These ways will help you protect app ideas. Frequently Asked Questions? 1. Can I register my app idea itself at the DPMA? No. Germany has no registry for abstract ideas. You can register a trademark for the name, a design for visuals, or a patent for a technical invention. The idea stays free. Copyright protects your code automatically, but it does not protect the concept behind it. 2. Does copyright protect my mobile app automatically? Yes. Sec. 69a UrhG protects software from creation, no filing needed. Keep proof like Git history and dated builds. Remember the limit, only the expression is protected, not the underlying idea or principle. That's why clean-room rebuilds happen. 3. Do I need a patent for my app in Germany? Usually not. Most apps are business logic and UI flows, which are excluded. A patent makes sense only for a novel technical solution. Consider the twenty-year term, rising annual fees, and attorney costs before you file. For most, it's overkill. 4. What must an NDA for app development include in Germany? Parties, purpose, clear definition of confidential info, handling rules, term, and return or deletion. German law also requires you to show appropriate measures. Avoid hidden IP grabs in NDAs, they are often ineffective. Keep it clear and proportional. 5. Who owns code from freelancers versus employees? Freelancers own what they write, but German law implies you get the usage rights needed for the contract's purpose if nothing is written. Those implied rights are narrow and non-exclusive. Employees are different, under Sec. 69b UrhG exploitation rights for software automatically lie with the employer, and for inventions the ArbnErfG automatically transfers rights to the employer unless explicitly released within four months, with compensation due. 6. How much does a German software trademark cost? EUR 290 for an electronic filing covering up to three Nice classes. Each extra class is EUR 100. Accelerated examination is EUR 200 extra. Many apps file in classes 9 and 42. Plan for attorney fees on top if you use one. 7. Can a US NDA work for a German developer? German courts enforce NDAs, but they apply German substantive law to trade secrets. Use a German-law version with jurisdiction in Germany, reference GeschGehG, and keep language clear. That avoids enforceability headaches later.
Read More
What Is the Real State of AI Integration for Businesses Today? The noise around artificial intelligence is deafening. Every vendor promises the unattainable. Organizations severely underestimate what it takes to move from a prototype to a production ready system. It takes serious engineering. Companies jump into projects without a clear goal. They burn through cash, frustrate their teams by skipping the absolute basics. Treat AI like any other major infrastructure investment. Finding an experienced AI software development company makes a massive difference right out of the gate. You need people who know exactly where the landmines are hidden. We are moving past the era of casual experimentation, Business leaders want measurable outcomes. They want tools that work when plugged into legacy systems. If your project doesn't solve a specific operational headache, it probably should not exist. How Should You Approach Planning Before Burning Cash? You can't throw money at an algorithm and hope it learns. Planning dictates your survival. First identify the exact problem. Not a vague idea like making things faster. You need a specific target. Think about reducing customer support ticket times by thirty percent. That defines a solid baseline. Data is your next massive hurdle. If your data is a mess, your output will be a mess. Most companies assume their databases are ready. They're almost always wrong. Proper data preparation is non-negotiable. You must audit what you have and figure out what is missing. Partnering with a solid AI software development company early saves you from building on quicksand. They tell you exactly what pipelines need fixing immediately. You are not just writing code anymore. You are training logic. Start small. Prove the concept. Scale up only after the data proves it works. What Are the Core Components and Top High Value Use Cases? Let's look at what actually moves the needle. The engine running these operations usually relies on specific machine learning models trained entirely on your proprietary data. That is where your real competitive advantage lives. You want a system understanding your specific industry jargon. Customer service is the obvious starting point. Tools powered by natural language processing handle massive volumes of basic inquiries. They route complex issues to human agents. This cuts wait times drastically. Supply chain logistics heavily utilize predictive analytics right now. Algorithms analyze weather patterns and historical sales to prevent stockouts. That is real money saved. Quality control in manufacturing is another huge growth area. Computer vision systems inspect parts on assembly lines instantly. An established AI software development company can look at your operations and instantly spot these high value opportunities. They know what works because they have deployed it globally. What Does a Reliable Implementation Framework Look Like? Building these systems requires strict discipline to prevent total chaos. You start with the data ingestion layer. You pull information from your CRMs and outdated flat files. Then comes the transformation layer. You clean the data and make it digestible. Mess up this step and the whole house of cards collapses. Next is the actual modeling environment. This involves rigorous testing. You validate the models against real world scenarios. You deploy custom solutions securely. They must not leak sensitive company data to the public internet. Ignore compliance protocols and you face massive regulatory fines. Once deployed, you need an inference engine that handles the load. This takes robust cloud architecture. A competent AI software development company sets up continuous monitoring from day one. Models degrade over time. Customer behaviors shift. You need a framework that automatically flags performance drops and triggers retraining cycles immediately. What Are the Real Costs, ROI Metrics, and Best Practices? Entry level automation projects run between twenty and eighty thousand dollars. Mid level applications with custom integrations cost up to two hundred and fifty thousand. Enterprise grade infrastructure requires half a million or more. Ongoing cloud compute costs easily take another twenty percent of that budget annually. But the return on investment completely justifies the upfront pain if executed correctly. You measure this through strict reductions in operational costs. Think fewer support hours and reduced equipment downtime. If your predictive engine increases cross sales by five percent, the system pays for itself in months. Bottom line. Best practices are simple. Don't build from scratch if an existing API works. Focus relentlessly on data quality. Invest heavily in change management. Your employees need training. Hiring an experienced AI software development company ensures you avoid these rookie mistakes. They keep the project grounded in reality. How Do We Wrap This Up for Maximum Impact? The global technology landscape shifts incredibly fast today. Brand new models drop every single week now. But the basic rules of running a successful business have not changed one single bit. You still need to solve real problems for your customers. You still need to watch your profit margins closely. Artificial intelligence is simply the newest lever to achieve those critical goals. Stop getting distracted by all the hype. Focus strictly on your internal data instead. Pick a highly specific, painful problem in your daily operations. Build a minimum viable product to tackle it. Prove that it actually saves money. Then slowly scale it across the entire company.Calculate the exact hiring cost of dedicated resources using WebOConnect’s quote calculator. Frequently Asked Questions? 1.How much does a basic business AI project cost? Basic implementations usually start around twenty thousand dollars. Costs easily scale up to eighty thousand depending on the integrations required. Start small, validate the tool, and prove the core value first 2.How long does it take to deploy an initial model? Expect a proof of concept to take anywhere from four to twelve weeks to complete. This timeline depends heavily on how clean your existing data is right now. Messy databases cause significant delays. 3. Do we need to hire an internal team immediately? Not usually. Many businesses partner with external engineering experts to build the first few applications. This keeps your initial overhead low while you test the waters. Hire internal engineers later. 4. What is the biggest hidden cost in these projects? Data preparation absolutely consumes the largest chunk of your budget. Many companies are shocked when formatting takes up sixty percent of the project time. Ongoing cloud computing costs also surprise executives. 5.How do we measure success for these initiatives? Track strict business metrics like reduced operational costs or increased daily sales conversions. Never measure success purely by technical metrics alone. If it doesn't improve the bottom line, it fails. 6. Are prebuilt solutions better than custom builds? Prebuilt tools always offer a faster and cheaper starting point for solving common business problems. Custom builds are only necessary when you have highly unique workflows. Always test an off the shelf option first. 7. What causes most of these implementations to fail? Lack of specific business goals and poor data quality are the two biggest project killers. Companies also regularly fail to train their staff properly. Without solid user adoption, algorithms are completely useless.
Read More
If organizations plan to hire dedicated developers in 2026 they then enter a market shaped by senior scarcity, AI output, and nearshore preference. Hiring is higher than usual. The numbers show 74% of developers say finding a job remains difficult. Senior hiring grew 19%, Lead roles 22%, Junior only 9%. The supply skews hard toward experienced engineers. Meanwhile, 90% of developers now use AI assistants. AI writes roughly 29% of the code and 67% say the pressure to ship faster has increased. The current situation has also made budgets tight, expectations climb. Early-2026 research links nearshore work to higher success rates, better quality, less PM overhead, fewer communication breakdowns than far-offshore setups. Methodology, not geography, moves the cost needle most. A 2008 trust study also found communication improves when trust is present. It reduces opportunistic behavior. How should planning be handled? Teams that hire dedicated developers without documenting scope report higher rework, so successful briefs define a 90-day outcome and list features, integrations, and compliance needs, then select from three engagement models. Staff augmentation fills gaps quickly which is often 2 to 4 weeks. The dedicated team model provides a fully cross-functional unit for long-term work. Fixed-price fits only locked scope not leading to complete potential. Mixing models mid-project raises overhead. Global hourly rates span $15 to $80, monthly offshore engagements range $800 to $8,000. Documenting time zone overlap early prevents friction later. By 2025, US firms had integrated remote teams into agile workflows. Nearshore hiring in Latin America grew for overlapping hours. A 2025 study found team composition significantly influences performance in onsite-offshore teams. Heterogeneities hinder knowledge growth leading to better output, exceeding expectations. Operational capabilities in mediated offshore models also depend on human resources and organizational age. What are the core components that actually drive cost? Not every project requires a full time in house hire. The modern contract economy offers distinct paths to get your code written. You need to match the engagement model to your specific risk tolerance and timeline. First, there's the classic fixed price contract. You hand over a scope of work, they give you a price, and they deliver the product. It sounds incredibly safe for your budget but rarely survives contact with reality. Software requirements change weekly due to user feedback. Fixed price contracts reduce agility and often leads to rushed, brittle code at the finish line because the vendor just wants to close the ticket. Then you have standard staff augmentation. This is where you lease talent by the hour to plug gaps in your existing roster. It works exceptionally well if you already have robust engineering processes. The most practical approach for scaling companies is often to hire dedicated developers through a structured agency. This model gives you a full time engineer who acts like an internal employee but remains on the vendor's payroll. They work over time, work for the company like their own, be accountable and align with your company. It's one of the most reliable staffing solutions available because it balances accountability with flexibility. What framework should teams follow to hire? A documented framework helps companies hire dedicated developers in under two weeks. Start with a one-page brief, Keep it tough. Then source from two channels max. More channels increase noise. Step three is a vetting process based on real work. Data shows 66% prefer practical challenges over puzzles. So use a paid 4 to 8 hour task mirroring production. Then a trial week with repo access. Then contract with IP transfer and security standards. Dedicated teams report 95% plus client retention when knowledge stays in the team. When a freelancer leaves, knowledge walks out. What are the best practices in 2026? Organizations that retain talent after they hire dedicated developers integrate them into Slack, Jira, Zoom, with no separate channels, and document expectations with agile ceremonies included. Security follows SSO, least privilege, mandatory review. Providers hold CMMI 5, SOC 2, ISO 27001. Yet 40% plan to leave within a year, citing pay and growth. Retention correlates with learning paths and centralized documentation. Best practices measure outcomes not hours. Velocity. Defect escape rate. Nearshore teams see fewer communication problems. Heterogeneous teams without planning show more “latent” errors. Centers that adjust working hours for overlap report fewer delays. Research notes “nearshore” clearly reduces management effort and improves quality today. Summary Building a great engineering team (and the larger company around that team) takes time, but most importantly it is a patience game. The days of treating code like a commodity are gone. The world is too competitive and good talent knows its worth no matter where you are. Map your technical needs against your actual management bandwidth before burning a dime. Pick an engagement model that works with your roadmap, not against it. Screen heavily for problem solving and communication, not just textbook knowledge. FAQs 1. How much does a senior offshore software engineer actually cost? In India, seniors usually run $45-70/hour (about $2500-$12k/month based on stack & engagement). Across offshore markets, you’ll see seniors going for $4k-6.5k/month. South Asia hovers at around $30-60/hour, while North America lands at $140-200. 2. How long should the technical interview process take? Five to seven business days, max. Move faster and you'll miss red flags in their code. Drag it out and you'll lose the best people to faster offers, guaranteed. Keep it tight: a quick screening call, one live technical, and a final culture-fit chat. That's it. No marathon loops. 3. Do I need a technical co-founder to build a remote team? You don't need a co-founder, but you do need understanding of the final product and making the technical team understand, also keep note of source code and details related to the final output making you independent. If that's not you, hire a fractional CTO, even part-time, to understand candidates and review the early architecture. 4. What is the biggest hidden cost of remote engineering? The largest hidden cost is always management overhead and the cost of poorly written code. If your internal team spends 15 hours a week fixing bugs created by a remote worker, your cheap hourly rate is actually costing you a fortune. Quality assurance and rework will drain your budget if vetting is poor. 5. Should I pay developers by the hour or a flat monthly fee? A flat monthly fee for a full time commitment is usually the best approach for ongoing product development. It creates predictability for your budget and gives the engineer a sense of stability. Hourly billing makes sense only for short term maintenance or highly specialized consulting work. 6. How do I handle timezone differences effectively? You must mandate a minimum of three to four hours of overlap between your core team and the remote engineers. Use this synchronous time strictly for unblocking tasks, code reviews, and sprint planning. Keep all other updates asynchronous through well written documentation and task trackers. 7. Is it safe to share my proprietary code with an external vendor? Yes, it's safe, as long as you put the right legal and technical safeguards in place from day one. Use solid NDAs and make sure the contract clearly gives your company all the IP rights. Then lock down repo access with role-based permissions and run regular security audits.
Read More
What should you know first? German law doesn't care about the spark in your head. It cares about what you build. Code. Designs. The name users see. How you keep secrets. That's it. If you want to protect app ideas in Germany, start with this legal fact. Sec. 69a UrhG protects software in any form, even drafts. Ideas and principles underneath? Not protected. Every commentary says the same. The code gets copyright, the concept stays free. How do you plan before sharing anything? The first move to protect app ideas is to separate ownership from the person. Most founders in Germany spin up a UG or GmbH early. Not for tax tricks. Because Sec. 69b UrhG puts exploitation rights with the employer for employee-created software. Clean. Simple. For freelancers, German law implies limited usage rights under the purpose-of-transfer doctrine (§31 Abs.5 UrhG) if you have no written contract. You can use what you paid for, but those implied rights are narrow and non-exclusive. To secure exclusive, worldwide rights, a written transfer remains practically mandatory. That's why an app development agreement matters before the first commit. Next, confidentiality. An NDA for app development works in Germany, courts enforce clear ones. But the Trade Secrets Act adds three hurdles. Is it a secret? Does it have commercial value? Did you take appropriate steps? That means limit repo access. Mark decks vertraulich. Log who saw what. A template without behavior fails in practice. This is basic legal protection for startups, not paperwork theater. What are the core parts of app intellectual property Germany uses? You cannot protect an app idea as an abstract thought, only its expressions. So you stack tools, each does one job. Copyright for mobile apps is automatic. Covers source, UI elements, graphics, docs. Doesn't cover the function. Keep Git timestamps, Figma versions, dated builds. That's your proof trail when someone claims they wrote it first. A software trademark Germany filing is for a brand. File at DPMA, classes 9 and 42 for most apps. EUR 290 electronically for up to three classes, EUR 100 each extra. Ten years, renewable. Do it before launch. I've watched teams rebrand at month nine because they skipped the search. Expensive. A patent app idea Germany founders ask about? Usually no. Patents aren't for business methods. They're for actual technical inventions. Got real tech? Then budget for it. Seriously. Filing starts cheap, around EUR 40 to 60. The examination is at least EUR 350. After that the annual fees creep up. Year three is EUR 70. By year twenty you're at EUR 2,030. And that's before the attorney. Expect another EUR 3,000 to 6,000 on top. Most consumer apps skip this and invest in brands and contracts instead. Trade secrets cover know-how you don't file. The law applies, but only if you act like it's secret. NDAs plus access logs plus marking. That's the combo German courts look for. No theater. What step-by-step framework works in Germany? This framework is how teams protect app ideas without wasting money on unnecessary filings. Document the concept first. One pager, sketches, export a dated PDF, store it in the company drive, not your personal Dropbox. Incorporate, make the entity the owner from day one. Run a trademark search in DPMAregister and EUIPO, then file early. If you need speed, pay EUR 200 for accelerated examination, and make a decision within six months if you cooperate. Sign NDAs before any deep dive, define purpose and term and return or deletion. Contact everyone. Freelancers get full IP assignment to avoid relying on implied narrow rights. Employees fall under Sec. 69b for software and the Employee Invention Act for inventions. Staff must report inventions, and under the reformed ArbnErfG the rights automatically transfer to the employer unless the employer explicitly releases the invention in text form within four months. Rights do not revert unless actively released, though compensation remains due. Use a private repo. Turn on access logs. Require signed commits. Get your DSGVO privacy policy, terms, and imprint live before beta, not after. Do it in that order and your chain of title stays clean. Skip one piece and you'll be patching holes later. So what actually works after launch? Long-term habits are what actually protect app ideas after launch. Keep one folder for all signed NDAs, assignments, licenses. Investors will ask, missing papers kill deals. Localize templates to German law and jurisdiction, reference BGB and GeschGehG, don't just use a US form. Monitor app stores monthly for copycats, your trademark gives you a fast takedown. Check open-source licenses before merging, non-compliance can lead to copyright infringement even for partial code, and Sec. 106 UrhG allows criminal liability. Train the team. Most leaks aren't hackers. They're screenshots. Shared test accounts. Sloppy Slack threads. Renew your marks at year nine, not year ten. Set the reminder now. It's boring admin work. That's what wins cases. Summary Copyright starts the second you type. No forms. No registry. Trademarks? They lock the brand at the DPMA, ten years at a time. Patents cover real technical inventions for twenty years, not typical app logic. Trade secrets work only if you take real steps, not just a signed PDF. And employees versus freelancers? Completely different rules for who owns what on day one. That's the whole map in five lines. These ways will help you protect app ideas. Frequently Asked Questions? 1. Can I register my app idea itself at the DPMA? No. Germany has no registry for abstract ideas. You can register a trademark for the name, a design for visuals, or a patent for a technical invention. The idea stays free. Copyright protects your code automatically, but it does not protect the concept behind it. 2. Does copyright protect my mobile app automatically? Yes. Sec. 69a UrhG protects software from creation, no filing needed. Keep proof like Git history and dated builds. Remember the limit, only the expression is protected, not the underlying idea or principle. That's why clean-room rebuilds happen. 3. Do I need a patent for my app in Germany? Usually not. Most apps are business logic and UI flows, which are excluded. A patent makes sense only for a novel technical solution. Consider the twenty-year term, rising annual fees, and attorney costs before you file. For most, it's overkill. 4. What must an NDA for app development include in Germany? Parties, purpose, clear definition of confidential info, handling rules, term, and return or deletion. German law also requires you to show appropriate measures. Avoid hidden IP grabs in NDAs, they are often ineffective. Keep it clear and proportional. 5. Who owns code from freelancers versus employees? Freelancers own what they write, but German law implies you get the usage rights needed for the contract's purpose if nothing is written. Those implied rights are narrow and non-exclusive. Employees are different, under Sec. 69b UrhG exploitation rights for software automatically lie with the employer, and for inventions the ArbnErfG automatically transfers rights to the employer unless explicitly released within four months, with compensation due. 6. How much does a German software trademark cost? EUR 290 for an electronic filing covering up to three Nice classes. Each extra class is EUR 100. Accelerated examination is EUR 200 extra. Many apps file in classes 9 and 42. Plan for attorney fees on top if you use one. 7. Can a US NDA work for a German developer? German courts enforce NDAs, but they apply German substantive law to trade secrets. Use a German-law version with jurisdiction in Germany, reference GeschGehG, and keep language clear. That avoids enforceability headaches later.
Read More